2.3 教師あり機械学習アルゴリズム
2.3.1 サンプルデータセット
- 人工的な単純なデータセットと、実世界の割と複雑なデータセットを使う。
2.3.1.1 人工的な単純なデータセット
単純なデータセットはmglearnで生成する。
- forge:
mglearn.datasets.make_forge()で生成する2クラス分類向けデータ。- 2つの特徴量と1つの2値目的変数をもつ。
X, y = mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.legend(["Class 0", "Class 1"], loc = 4) # 凡例
plt.xlabel("第1特徴量")
plt.ylabel("第2特徴量")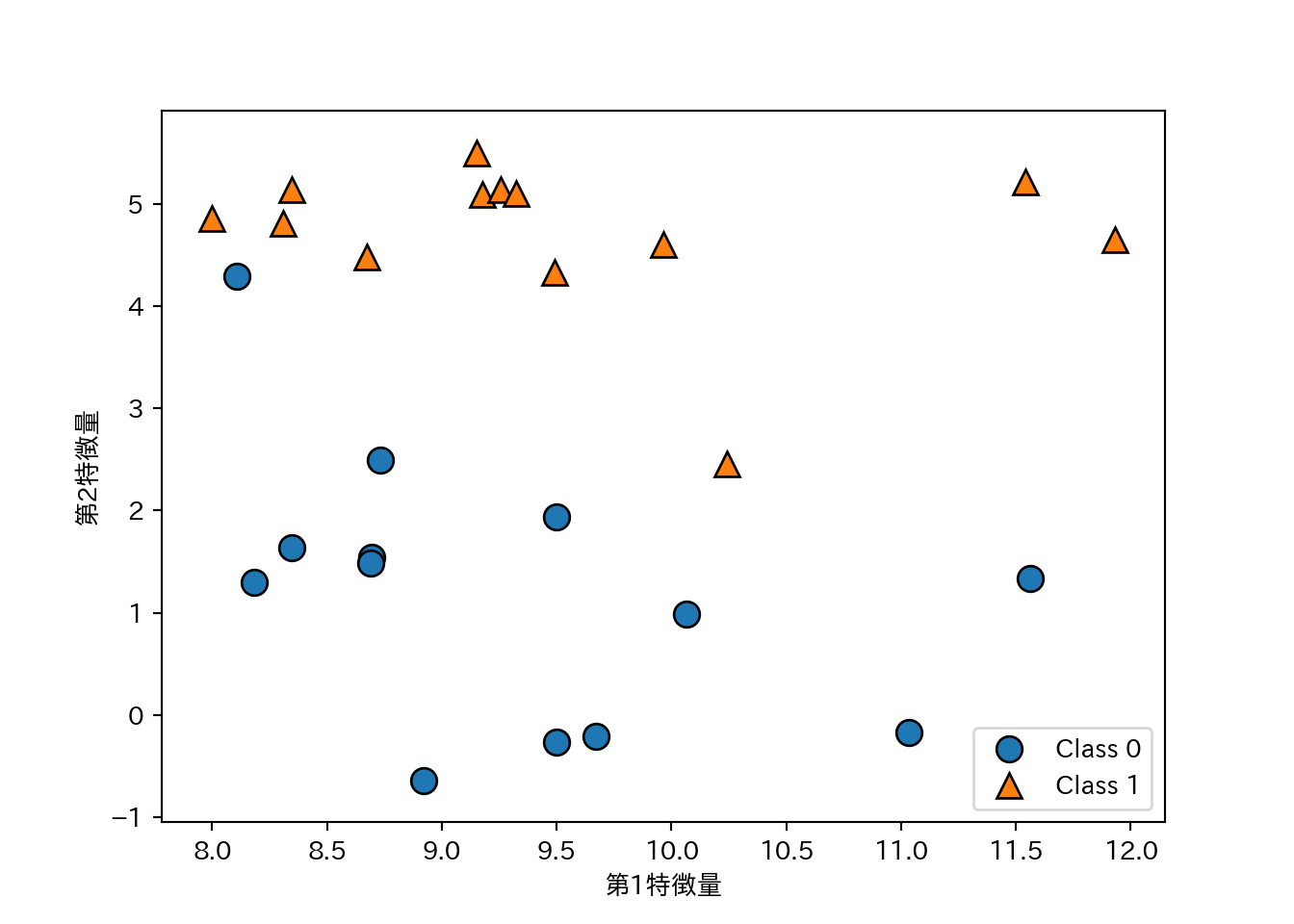
- wave:
mglearn.datasets.make_waveで生成する回帰向けデータ。- 1つの特徴量と1つの目的変数を持つ。
X, y = mglearn.datasets.make_wave(n_samples = 40)
plt.plot(X, y, 'o')
plt.xlabel("特徴量")
plt.ylabel("目的変数")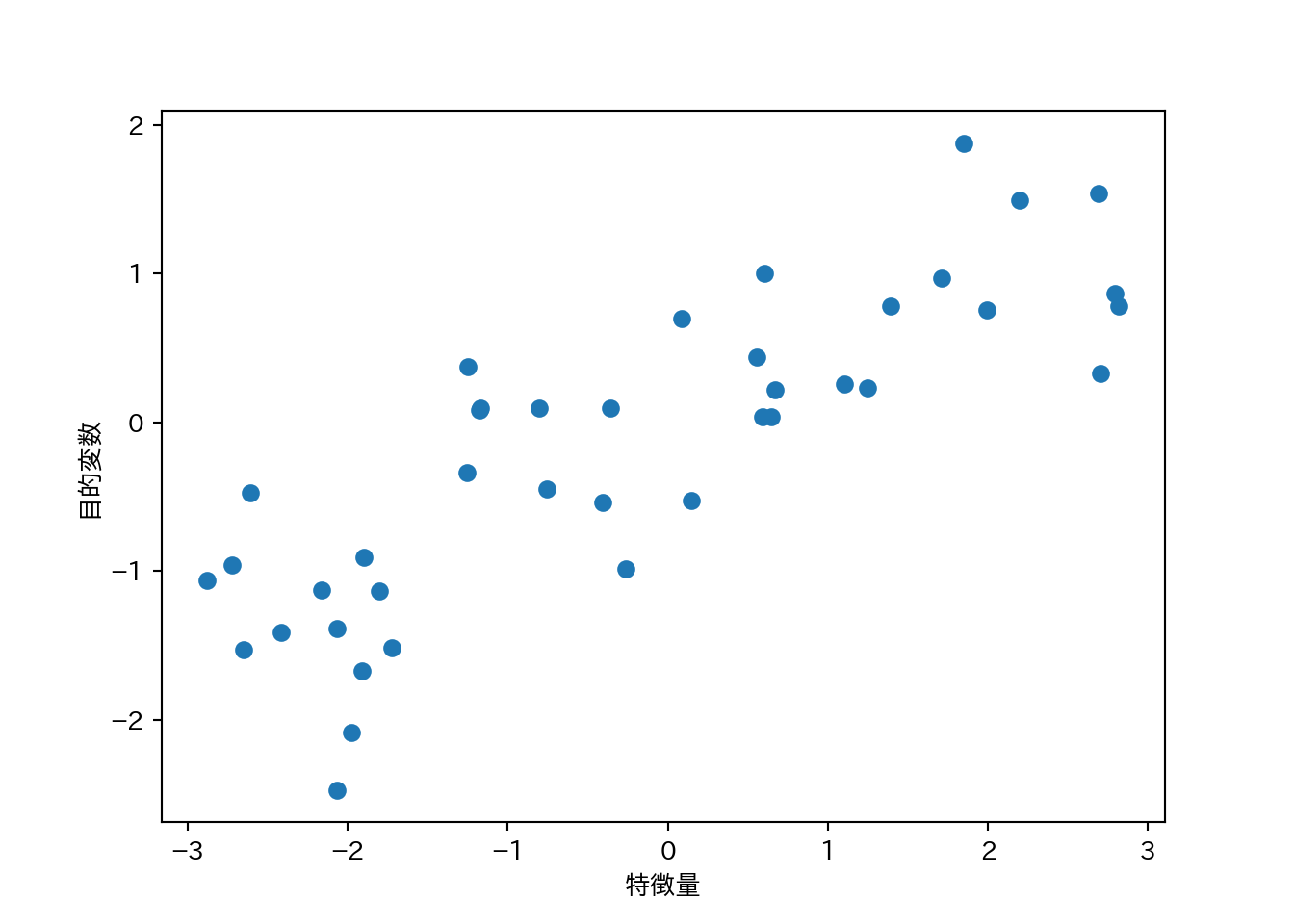
2.3.1.2 実データ
実データはscikit-learnに入ってるものを使う。第1章でも説明したBunchクラスになっている。
- cancer: ウィスコンシン乳癌データセット
- 目的変数は良性(benign)と悪性(malignant)の2値。
- 特徴量は30。
- データポイントは569点。
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print(cancer.keys())
## dict_keys(['target', 'data', 'DESCR', 'target_names', 'feature_names'])
print(cancer.data.shape)
## (569, 30)
print(cancer.target_names)
## ['malignant' 'benign']
print(np.bincount(cancer.target))
## [212 357]- boston_housing: 1970年代のボストン近郊の住宅価格。
- 住宅価格の中央値が目的変数。
- 特徴量は13。
- データポイントは506点。
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)
## (506, 13)
print(boston.feature_names)
## ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
## 'B' 'LSTAT']- 特徴量同士の積を求めたりして、新しい特徴量を導出することを特徴量エンジニアリングと呼ぶ。
- boston_housingに対し、重複ありで2つの特徴量の積を求め、データセットの拡張を試みる。
- 作業が面倒なので既に拡張したものが
mglearn.datasets.load_extended_boston()で読み込めます。
- 作業が面倒なので既に拡張したものが
X, y = mglearn.datasets.load_extended_boston()
print(X.shape)
## (506, 104)