Section 9 ハイパーパラメータのチューニング
多くの機械学習アルゴリズムはハイパーパラメータを持っている。学習器のチュートリアルでも説明したが、ハイパーパラメータとして特定の値を設定したければその値をmakeLearnerに渡すだけで良い。しかし、ハイパーパラメータの最適な値というのは大抵の場合は自明ではなく、できれば自動的に調整する手法が欲しい。
機械学習アルゴリズムをチューニングするためには、以下の点を指定する必要がある。
- パラメータの探索範囲
- 最適化アルゴリズム(チューニングメソッドとも呼ぶ)
- 評価手法(すなわち、リサンプリング手法と性能指標)
パラメータの探索範囲: 例としてサポートベクターマシン(SVM)におけるパラメータCの探索範囲を指定してみよう。
ps = makeParamSet(
makeNumericParam("C", lower = 0.01, upper = 0.1)
)最適化アルゴリズム: 例としてランダムサーチを指定してみよう。
ctrl = makeTuneControlRandom(maxit = 100L)評価手法: リサンプリング手法として3分割クロスバリデーションを、性能指標として精度を指定してみよう。
rdesc = makeResampleDesc("CV", iter = 3L)
measure = acc評価手法の指定方法については既に説明したところであるので、ここから先は探索範囲と最適化アルゴリズムの指定方法と、チューニングをどのように行い、結果にどのようにアクセスし、さらにチューニング結果を可視化する方法について幾つかの例を通して説明していこう。
このセクションを通して、例としては分類問題を取り上げるが、他の学習問題についても同様の手順で実行できるはずだ。
このさき、irisの分類タスクを使用して、SVMのハイパーパラメータを放射基底関数(RBF)カーネルを使ってチューニングする例を説明する。以下の例では、コストパラメータCと、RBFカーネルのパラメータsigmaをチューニングする。
9.1 パラメータ探索空間の指定
チューニングの際にまず指定しなければならないのは値の探索範囲である。これは例えば“いくつかの値の中のどれか”かもしれないし、“\(10^{-10}\)から\(10^{10}\)までの間の中のどこか”かもしれない。
探索空間の指定に際して、パラメータの探索範囲についての情報を含むParamSetオブジェクトを作成する。これにはmakeParamSet関数を用いる。
例として、パメータCとsigmaの探索範囲を両方共0.5, 1.0, 1.5, 2.0という離散値に設定する例を見よう。それぞれのパラメータにどのような名前が使われているのかは、kernlabパッケージで定義されている(cf. kernlab package | R Documentation)。
discrete_ps = makeParamSet(
makeDiscreteParam("C", values = c(0.5, 1.0, 1.5, 2.0)),
makeDiscreteParam("sigma", values = c(0.5, 1.0, 1.5, 2.0))
)
discrete_ps$> Type len Def Constr Req Tunable Trafo
$> C discrete - - 0.5,1,1.5,2 - TRUE -
$> sigma discrete - - 0.5,1,1.5,2 - TRUE -連続値の探索範囲を指定する際にはmakeDiscreteParamの代わりにmakeNumericParamを使用する。また、探索範囲として\(10^{-10}\)から\(10^{10}\)のような範囲を指定する際には、trafo引数に変換用の関数を指定できる(trafoはtransformationの略)。変換用の関数を指定した場合、変換前のスケールで行われ、学習アルゴリズムに値を渡す前に変換が行われる。
num_ps = makeParamSet(
makeNumericParam("C", lower = -10, upper = 10, trafo = function(x) 10^x),
makeNumericParam("sigma", lower = -10, upper = 10, trafo = function(x) 10^x)
)他にも数多くのパラメータが利用できるが、詳しくはmakeParamSet function | R Documentationを確認してもらいたい。
パラメータをリストの形で指定しなければならない関数もあるが、mlrを通じてその関数を扱う場合、mlrはできるかぎりリスト構造を除去し、パラメータを直接指定できるように試みる。例えばSVMを実行する関数のksvmは、kpar引数にsigmaのようなカーネルパラメータをリストで渡す必要がある。今例を見たように、mlrはsigmaを直接扱うことができる。この仕組みのおかげで、mlrは様々なパッケージの学習器を統一したインターフェースで扱うことができるのだ。
9.2 最適化アルゴリズムの指定
パラメータの探索範囲を決めたら次は最適化アルゴリズムを指定する。mlrにおいて最適化アルゴリズムはTuneControlクラスのオブジェクトとして扱われる。
グリッドサーチは適切なパラメータを見つけるための標準的な(しかし遅い)方法の一つだ。
先に例を挙げたdiscrete_psの場合、グリッドサーチは単純に値の全ての組合せを探索する。
ctrl = makeTuneControlGrid()num_psの場合は、グリッドサーチは探索範囲をまず均等なサイズのステップに分割する。標準では分割数は10だが、これはresolution引数で変更できる。ここではresolutionに15を指定してみよう。なお、ここで言う均等な15分割というのは、10^seq(-10, 10, length.out = 15)という意味である。
ctrl = makeTuneControlGrid(resolution = 15L)クロスバリデーション以外にも多くの最適化アルゴリズムが利用可能であるが、詳しくはTuneControl function | R Documentationを確認してもらいたい。
グリッドサーチは一般的には遅すぎるので、ランダムサーチについても検討してみよう。ランダムサーチはその名の通り値をランダムに選択する。maxit引数に試行回数を指定できる。
ctrl = makeTuneControlRandom(maxit = 200L)9.3 チューニングの実行
パラメータの探索範囲と最適化アルゴリズムを決めたら、いよいよチューニングの実行の時だ。あとは、リサンプリング手法と評価尺度を設定する必要がある。
今回は3分割クロスバリデーションをパラメータ設定の評価に使用する。まずはリサンプリングdescriptionを生成する。
rdesc = makeResampleDesc("CV", iters = 3L)では、今まで作成したものを組合せて、tuneParams関数によりパラメータチューニングを実行しよう。今回はdiscrete_psに対してグリッドサーチを行う。
ctrl = makeTuneControlGrid()
res = tuneParams("classif.ksvm", task = iris.task, resampling = rdesc,
par.set = discrete_ps, control = ctrl)$> [Tune] Started tuning learner classif.ksvm for parameter set:$> Type len Def Constr Req Tunable Trafo
$> C discrete - - 0.5,1,1.5,2 - TRUE -
$> sigma discrete - - 0.5,1,1.5,2 - TRUE -$> With control class: TuneControlGrid$> Imputation value: 1$> [Tune-x] 1: C=0.5; sigma=0.5$> [Tune-y] 1: mmce.test.mean=0.0533; time: 0.0 min$> [Tune-x] 2: C=1; sigma=0.5$> [Tune-y] 2: mmce.test.mean=0.0533; time: 0.0 min$> [Tune-x] 3: C=1.5; sigma=0.5$> [Tune-y] 3: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 4: C=2; sigma=0.5$> [Tune-y] 4: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 5: C=0.5; sigma=1$> [Tune-y] 5: mmce.test.mean=0.0667; time: 0.0 min$> [Tune-x] 6: C=1; sigma=1$> [Tune-y] 6: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 7: C=1.5; sigma=1$> [Tune-y] 7: mmce.test.mean=0.0467; time: 0.0 min$> [Tune-x] 8: C=2; sigma=1$> [Tune-y] 8: mmce.test.mean=0.0533; time: 0.0 min$> [Tune-x] 9: C=0.5; sigma=1.5$> [Tune-y] 9: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 10: C=1; sigma=1.5$> [Tune-y] 10: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 11: C=1.5; sigma=1.5$> [Tune-y] 11: mmce.test.mean=0.0667; time: 0.0 min$> [Tune-x] 12: C=2; sigma=1.5$> [Tune-y] 12: mmce.test.mean=0.06; time: 0.0 min$> [Tune-x] 13: C=0.5; sigma=2$> [Tune-y] 13: mmce.test.mean=0.0667; time: 0.0 min$> [Tune-x] 14: C=1; sigma=2$> [Tune-y] 14: mmce.test.mean=0.0667; time: 0.0 min$> [Tune-x] 15: C=1.5; sigma=2$> [Tune-y] 15: mmce.test.mean=0.0667; time: 0.0 min$> [Tune-x] 16: C=2; sigma=2$> [Tune-y] 16: mmce.test.mean=0.06; time: 0.0 min$> [Tune] Result: C=1.5; sigma=1 : mmce.test.mean=0.0467res$> Tune result:
$> Op. pars: C=1.5; sigma=1
$> mmce.test.mean=0.0467tuneParamsはパラメータの全ての組み合わせに対してクロスバリデーションによる性能評価を行い、最も良い値を出した組合せをパラメータとして採用する。性能指標を指定しなかった場合は誤分類率(mmce)が使用される。
それぞれのmeasureは、その値を最大化すべきか最小化すべきかを知っている。
mmce$minimize$> [1] TRUEacc$minimize$> [1] FALSEもちろん、他の指標をリストとして同時にtuneParamsに渡すこともできる。この場合、最初の指標が最適化に使われ、残りの指標は単に計算されるだけとなる。もし複数の指標を同時に最適化したいと考えるのであれば、Advanced Tuning - mlr tutorialを参照してほしい。
誤分類率の代わりに精度(acc)を計算する例を示そう。同時に、他の性能指標として精度の標準偏差を求めるため、setAggregation関数を使用している。また、今回は探索範囲num_setに対して100回のランダムサーチを行う。100回分の出力は長くなるので、show.info = FALSEを指定している。
ctrl = makeTuneControlRandom(maxit = 100L)
res = tuneParams("classif.ksvm", task = iris.task, resampling = rdesc, par.set = num_ps,
control = ctrl, measures = list(acc, setAggregation(acc, test.sd)), show.info = FALSE)
res$> Tune result:
$> Op. pars: C=7.99e+03; sigma=5.62e-05
$> acc.test.mean=0.953,acc.test.sd=0.01159.4 チューニング結果へのアクセス
チューニングの結果はTuneResultクラスのオブジェクトである。見つかった最適値は$xスロット、性能指標については$yスロットを通じてアクセスできる。
res$x$> $C
$> [1] 7985.08
$>
$> $sigma
$> [1] 5.623177e-05res$y$> acc.test.mean acc.test.sd
$> 0.95333333 0.01154701最適化されたパラメータをセットした学習器は次のように作成できる。
lrn = setHyperPars(makeLearner("classif.ksvm"), par.vals = res$x)
lrn$> Learner classif.ksvm from package kernlab
$> Type: classif
$> Name: Support Vector Machines; Short name: ksvm
$> Class: classif.ksvm
$> Properties: twoclass,multiclass,numerics,factors,prob,class.weights
$> Predict-Type: response
$> Hyperparameters: fit=FALSE,C=7.99e+03,sigma=5.62e-05あとはこれまでと同じだ。irisデータセットに対して再度学習と予測を行ってみよう。
m = train(lrn, iris.task)
predict(m, task = iris.task)$> Prediction: 150 observations
$> predict.type: response
$> threshold:
$> time: 0.00
$> id truth response
$> 1 1 setosa setosa
$> 2 2 setosa setosa
$> 3 3 setosa setosa
$> 4 4 setosa setosa
$> 5 5 setosa setosa
$> 6 6 setosa setosa
$> ... (150 rows, 3 cols)しかし、この方法だと最適化された状態のハイパーパラメータの影響しか見ることができない。検索時に生成された他の値を使った場合の影響はどのように確認すれば良いだろうか?
9.5 ハイパーパラメータチューニングの影響を調査する
generateHyperParsEffectDataを使うと、サーチ中に生成された全ての値について調査を行うことができる。
generateHyperParsEffectData(res)$> HyperParsEffectData:
$> Hyperparameters: C,sigma
$> Measures: acc.test.mean,acc.test.sd
$> Optimizer: TuneControlRandom
$> Nested CV Used: FALSE
$> Snapshot of data:
$> C sigma acc.test.mean acc.test.sd iteration exec.time
$> 1 3.90155148 9.392509 0.2733333 0.02309401 1 0.051
$> 2 -0.47745952 3.929691 0.2733333 0.02309401 2 0.046
$> 3 0.99951412 9.447758 0.2733333 0.02309401 3 0.046
$> 4 6.24138379 -8.314684 0.8866667 0.03055050 4 0.047
$> 5 0.04530898 2.955353 0.2733333 0.02309401 5 0.046
$> 6 8.61392138 -5.444293 0.9400000 0.06928203 6 0.065この中に含まれているパラメータの値はオリジナルのスケールであることに注意しよう。trafoに指定した関数で変換後の値が欲しければ、trafo引数にTRUEを指定する必要がある。
generateHyperParsEffectData(res, trafo = TRUE)$> HyperParsEffectData:
$> Hyperparameters: C,sigma
$> Measures: acc.test.mean,acc.test.sd
$> Optimizer: TuneControlRandom
$> Nested CV Used: FALSE
$> Snapshot of data:
$> C sigma acc.test.mean acc.test.sd iteration exec.time
$> 1 7.971710e+03 2.468934e+09 0.2733333 0.02309401 1 0.051
$> 2 3.330738e-01 8.505326e+03 0.2733333 0.02309401 2 0.046
$> 3 9.988818e+00 2.803873e+09 0.2733333 0.02309401 3 0.046
$> 4 1.743347e+06 4.845250e-09 0.8866667 0.03055050 4 0.047
$> 5 1.109964e+00 9.023045e+02 0.2733333 0.02309401 5 0.046
$> 6 4.110753e+08 3.595068e-06 0.9400000 0.06928203 6 0.065また、リサンプリングの部分で説明したように、テストデータに加えて訓練データに対しても性能指標を求められることに注意してもらいたい。
rdesc2 = makeResampleDesc("Holdout", predict = "both")
res2 = tuneParams("classif.ksvm", task = iris.task, resampling = rdesc2, par.set = num_ps,
control = ctrl, measures = list(acc, setAggregation(acc, train.mean)), show.info = FALSE)
generateHyperParsEffectData(res2)$> HyperParsEffectData:
$> Hyperparameters: C,sigma
$> Measures: acc.test.mean,acc.train.mean
$> Optimizer: TuneControlRandom
$> Nested CV Used: FALSE
$> Snapshot of data:
$> C sigma acc.test.mean acc.train.mean iteration exec.time
$> 1 -9.6272136 2.46479089 0.28 0.36 1 0.028
$> 2 0.5922449 -2.19815745 0.98 0.94 2 0.028
$> 3 5.2125327 -0.46505868 0.96 1.00 3 0.026
$> 4 -1.1182917 3.99346631 0.28 0.36 4 0.025
$> 5 0.5484059 9.10947156 0.30 1.00 5 0.026
$> 6 3.8318971 0.04571449 0.96 1.00 6 0.025パラメータ値の評価結果はplotHyperParsEffect関数を使うと簡単に可視化できる。例を示そう。以下では、繰り返し毎の性能指標の変化をプロットしている。ここでresは先に示したものとほぼ同じだが、2つの性能指標を使用している。
res = tuneParams("classif.ksvm", task = iris.task, resampling = rdesc, par.set = num_ps,
control = ctrl, measures = list(acc, mmce), show.info = FALSE)
data = generateHyperParsEffectData(res)
plotHyperParsEffect(data, x = "iteration", y = "acc.test.mean", plot.type = "line")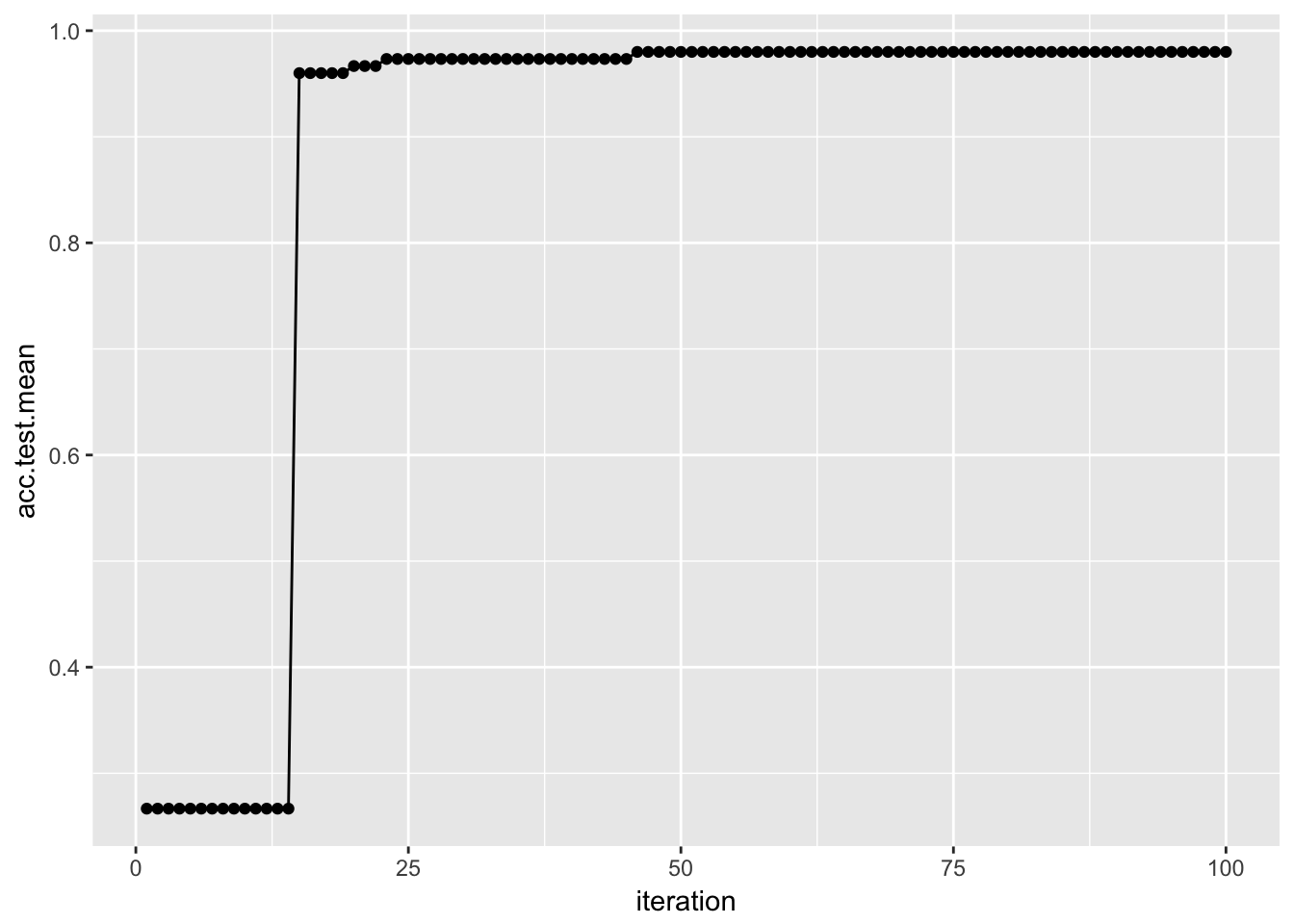
デフォルトではプロットされるのは現在の大域的な最適値のみであるという点に注意してほしい。これはglobal.only引数で制御できる。
ハイパーパラメータチューニング結果のプロットについてより詳細な話題はHyperparameter Tuning Effects - mlr tutorialを確認してほしい。
9.6 その他いろいろ
- 回帰や生存時間分析、その他のタスクについてもチューニングのやり方は変わらない。
- 時間のかかるチューニングで、数値エラーやその他のエラーで計算が停止してしまうのは非常に煩わしい。この点に関する解決策を得るには、
configureMlr関数のon.learner.error引数について調べてみると良いだろう。Configuration - mlr tutorialにこの件に関するチュートリアルがある。また、TuneControl function | R Documentationのimpute.val引数に関する情報も役立つだろう。 - チューニングは同じデータに対して継続的に実施するため、推定値は楽観的な方向にバイアスがかかっている可能性がある。バイアスのない推定値を得るためのより良いアプローチとしてnested resamplingがある。これは、モデル選択のプロセスを外部リサンプリングループに埋め込む。詳しくはNested Resampling - mlr tutorialを参照。